【Python】初心者必見!スクレイピングを行う方法について解説!

Pythonではスクレイピングを行うことができます。
スクレイピングとは、収集したデータを解析し、必要なデータを取得することであり、大量のデータを収集して行うデータ解析や、大量のデータを学習させる人工知能の開発などで使用されています。
しかし、スクレイピンングは他のサイトにアクセスして、情報を収集することになりますので、他のサイトに迷惑をかけないようにしてください。
今回は、Pythonでスクレイピングを行う方法について初心者の方でも分かりやすく解説していきます。
目次

今回はpythonでスクレイピングを行う方法について説明していきます。

はい!
お願いします!
スクレイピングとは
スクレイピングとは、収集したデータを解析し、必要なデータを取得することをいいます。
そのため、大量のデータを収集して行うデータ解析や、大量のデータを学習させる人工知能の開発などでスクレイピンングが使用されています。
スクレイピングを行う際の注意点
スクレイピンングを行う際に、注意しなければならないことがあります。
それは「他のサイトに迷惑をかけない」ということであり、以下の3点に気をつけるようにしましょう。
⚫︎ 著作権を守る
他人が作成した著作物は、使用許可があるもの以外は無断で複製したり使用したりしないようにしましょう。
それらを自分の勉強の範囲内で使用するのは構いませんが、公の場で公開してはいけません。
その為、他人が作成した著作物は自分の範囲内で使用するようにしましょう。
また、著作物を許可している情報のサイトがありますので、そちらを使用するようにしましょう。
⚫︎ 多くアクセスして業務の妨害をしない
サーバーに大量にアクセスしてしまうとサーバーに負荷がかかり、切断されたり、速度が遅くなったりしてしまいます。
そのため、「何分おきに行う」いうように自分でルールを設定して行うようにしましょう。
⚫︎ ローリング禁止の場所からクローリングしない
サイトをクローリングしてほしくないと思っているときは、そのページに表示があります。
これは「robot.txt」やHTMLの「robot metaタグ」に書いてありますので、確認しておきましょう。
スクレイピングは他のサイトにアクセスして情報を取得するので何回もアクセスするとサーバーに負荷がかかり、ダウンしてしまう可能性があるので迷惑をかけてしまいます。
その為、何分おきや何時間に何回など頻度を決めて行うようにしましょう。
分かりました!
スクレイピングを行うための準備
スクレイピングはを行うための準備について解説していきます。
準備は以下の通りに行っていくとすぐにできますのでとても簡単です。
Pythonをインストール
まずは、自分のPCにPythonをインストールしましょう。
Pythonのインストール方法についてはこちらをご参考ください。

requestsをインストールする
Pythonをインストールした後は、requestsをインストールしましょう。
requestsとはインターネットに簡単にアクセスできるライブラリ(モジュール)となります。
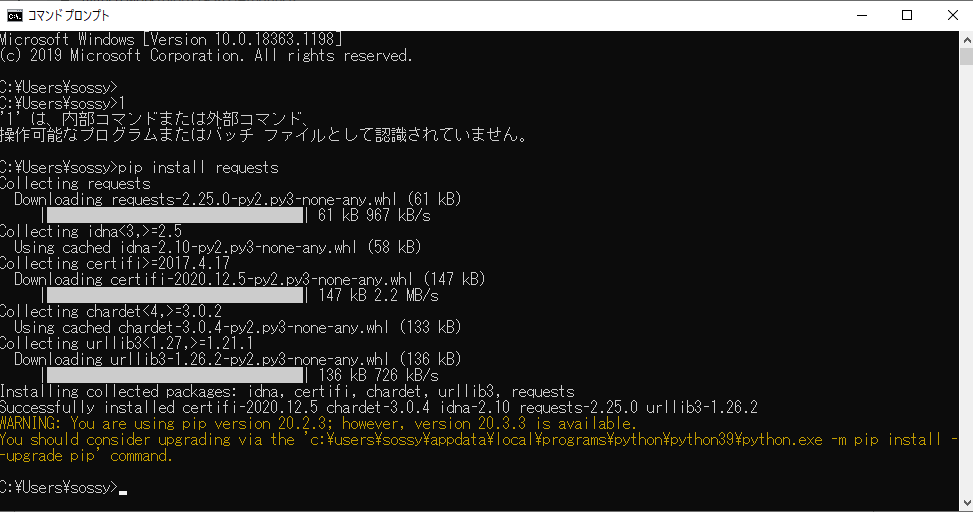
requestsをインストールするにはまず、[コマンドプロンプト]を起動します。
Macの場合は[ターミナル]を起動します。

[コマンドプロンプト]もしくは[ターミナル]を起動したら下記のコードを入力します。
Windowsの場合
|
1 |
pip install requests |
Macの場合
|
1 |
pip3 install requests |
すると、インストールが始まりますので、インストールが完了するとrequestsのインストールは完了です。
Beautiful Soupをインストールする
requestsをインストールしましたらBeautiful Soupをインストールしましょう。
Beautiful SoupとはHTMLを簡単に分析できるライブラリ(モジュール)となります。
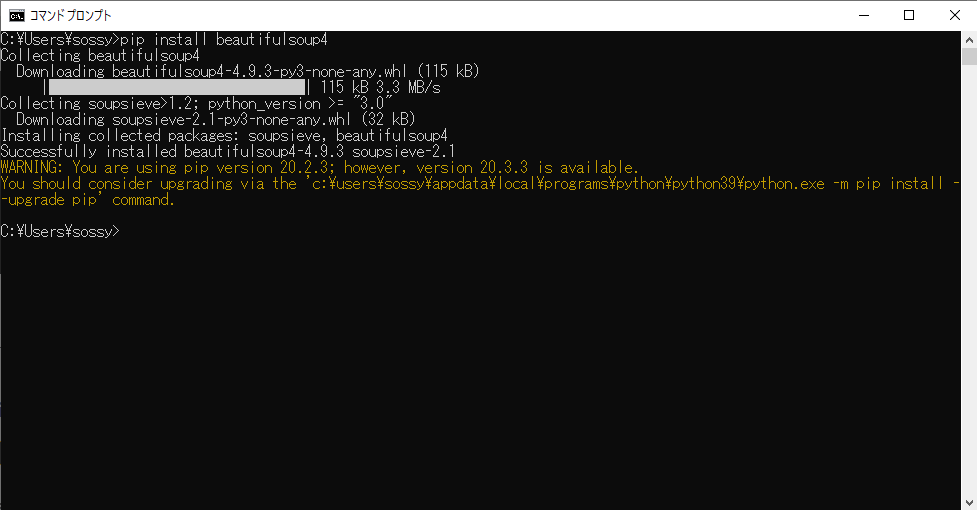
Beautiful Soupをインストールするには先ほどと同様に、[コマンドプロンプト]を起動します。
Macの場合は[ターミナル]を起動します。
[コマンドプロンプト]もしくは[ターミナル]を起動したら下記のコードを入力します。
Windowsの場合
|
1 |
pip install beautifulsoup4 |
Macの場合
|
1 |
pip3 install beautifulsoup4 |
すると、インストールが始まりますので、インストールが完了するとbeautifulsoupのインストールは完了です。
実際にスクレイピングを行ってみる
requestsとBeautiful Soupがインストールできましたら、実際にスクレイピングを行ってみましょう。
requestsでHTMLファイルを読み込んでみる
requestsモジュールを使って、実際にHTMLファイルを読み込んでみましょう。
「IDLE」を開いて、下記のコードを入力して実行してみます。
指定しているURLは私が作成したサイトになりますのでスクレイピンングの練習にしても構いません。
例
|
1 2 3 4 5 6 7 8 9 |
import requests url = "http://xd117075.wp.xdomain.jp/contact/" response = requests.get(url) response.encoding = response.apparent_encoding print(response.text) |
実行結果
<!DOCTYPE html>
<html lang=”ja”>
<head>
<meta charset=”UTF-8″>
<meta name=”viewport” content=”width=device-width, initial-scale=1.0″>
<title>Document</title>
<link rel=”stylesheet” href=”style.css”>
<script src=”https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js”></script>
</head>
<body><script type=”text/javascript” src=”https://ad.xdomain.ne.jp/js/server-wp.js”></script>
<h2>送信時に処理を実行させる</h2>
<form method= “post” action=”http://xd117075.wp.xdomain.jp/mail-send/”>
<input type=”text” name= “contens ” value=”テキストを入力する”>
<input type=”submit” class= “btn” value=”送信”>
</form>
<script src=”/themes/dazzling/index.js”></script>
</body>
</html>
requestによって、urlで指定したサイトのページのHTMLを取得しています。
その為、取得したHTMLが表示されます。
requestsを使用することで、HTMLファイルを読み込んでいますね!
そうですね。
requestsで指定したURLにアクセスし、text()メソッドでURLの要素をテキストで取得しています。
Beautiful Soupで取得したHTMLを解析する
Beautiful Soupモジュールを使って、取得したHTMLを解析してみましょう。
「IDLE」を開いて、下記のコードを入力して実行してみます。
指定しているURLも私が作成したサイトになりますのでスクレイピンングの練習にしても構いません。
例
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import requests from bs4 import BeautifulSoup load_url = "http://xd117075.wp.xdomain.jp/2020/11/27/ブログ45/" html = requests.get(load_url) soup = BeautifulSoup(html.content, "html.parser") print(soup.find("title")) print(soup.find("h2")) print(soup.find("h3")) |
実行結果
<title>ブログ45 – ブログ部屋</title>
<h2>ブログ45 </h2>
<h3><span id=”i-2″>ブログの小見出し</span></h3>
BeautifulSoupによって、urlで指定したサイトのページのHTMLを解析しています。
その為、指定したURLのtitleタグとh2タグとh3タグの要素が表示されています。
Beautiful Soupを使用することで、HTML内で取得したい要素のみを取得していますね!
そうですね。
もし、他のタグを取得したい場合はfind()メソッドのパラメータを変更すると良いですよ。
今回のポイント
スクレイピングを行うにはrequestsとBeautiful Soupを使用
⚫︎ Pythonでスクレイピングを行うにはrequestsとBeautiful Soupをインストールする
⚫︎ requestsとはインターネットに簡単にアクセスできるライブラリ(モジュール)である
⚫︎ Beautiful SoupでとはHTMLを簡単に分析できるライブラリ(モジュール)である
ST
株式会社flyhawkのSTです。フライテックメディア事業部でのメディア運営・ライター業務なども担当。愛機はMac Book AirとThinkPad。好きな言語:swift、JS系(Node.js等)。好きなサーバー:AWS。受託開発やプログラミングスクールの運営をしております。ご気軽にお問い合わせください。